I created my own YouTube algorithm (to stop me wasting time)
Using the YouTube API and Amazon’s AWS Lambda
🚀 Escaping the YouTube algorithm
I love watching YouTube videos that improve my life in some tangible way. Unfortunately, the YouTube algorithm doesn’t agree. It likes to feed me clickbait and other garbage.
This isn’t all that surprising. The algorithm prioritises clicks and watch time.
So I set out on a mission: Can I write code that will automatically find me valuable videos, eliminating my dependence on the YouTube algorithm?
Here’s how it went.
🗺️ The best laid plans
I started by visualising what I wanted the tool to do. I wanted something that would (i) rank videos based on likely relevance for me and (ii) automatically send me suggested videos, which I could select from.
I figured I could make some major productivity gains if I could batch-decide the videos I was going to watch each week and eliminate infinity scrolling YouTube browsing.

I knew I’d need the YouTube API to get video information (what’s an API?). I’d then create a formula which processed that information to rank videos. For the final step, I planned to set up an automated email to myself using AWS Lambda, which would list the top-ranked videos.
That’s not exactly how it ended up, though.
(If you want to skip the story and see the final code, click here.)
⛵️ Navigating the YouTube API
I wanted to find metrics that I could use to rank videos in terms of their likely interest to me.
I read through YouTube’s documentation here and saw that you can get information at the level of videos (title, when published, how many views, the thumbnail, etc) and at the channel level (number of subscribers, comments, views, channel playlists, etc).
Seeing this, I was pretty confident I could use this to define a metric and rank videos.
I obtained an API key through the developer console here and copied it into my Python script.
This enables you to initialise an API call and retrieve results with the following lines of code:
This would return a JSON object, which I could parse to find the appropriate information. For example, to find the date published, I could index results as follows:
🧮 Finding valuable videos: defining the formula
Now that I could query the appropriate information, I needed to use the values obtained to rank videos in terms of their interest to me.
This was a tricky one. What makes a good video? Is it the view count? The number of comments? The number of subscribers of the channel?
I decided to start with total view count, as a reasonable first-degree proxy of how valuable the video would be. In theory, videos that are interesting or well-explained will gain positive audience feedback, get promoted more and thus have more views.
However, there are a few things that total view count doesn’t take into account:
Firstly, if a channel has built up a large audience, then it will be much easier to get a comparable level of views compared to a smaller channel. Some of this may reflect more experience leading to better videos, but I didn’t want to discount potentially high-quality videos from smaller channels. A 100,000 view video from a channel with 10,000 subscribers is probably better than a 100,000 view video from a 1 million subscriber channel.
And secondly, videos can get lots of views for the wrong reasons, such as clickbait titles or thumbnails, or being controversial. I’m personally less interested in these types of video.
I needed to incorporate other metrics. The next one was subscriber count.
I tested ranking based solely on the view-to-subscriber ratio (ie. by dividing views by number of subscribers).
When I looked at the results, some of them looked promising. However, I did notice a problem: For videos with really small subscriber counts, the score would get heavily amplified and surface to the top.
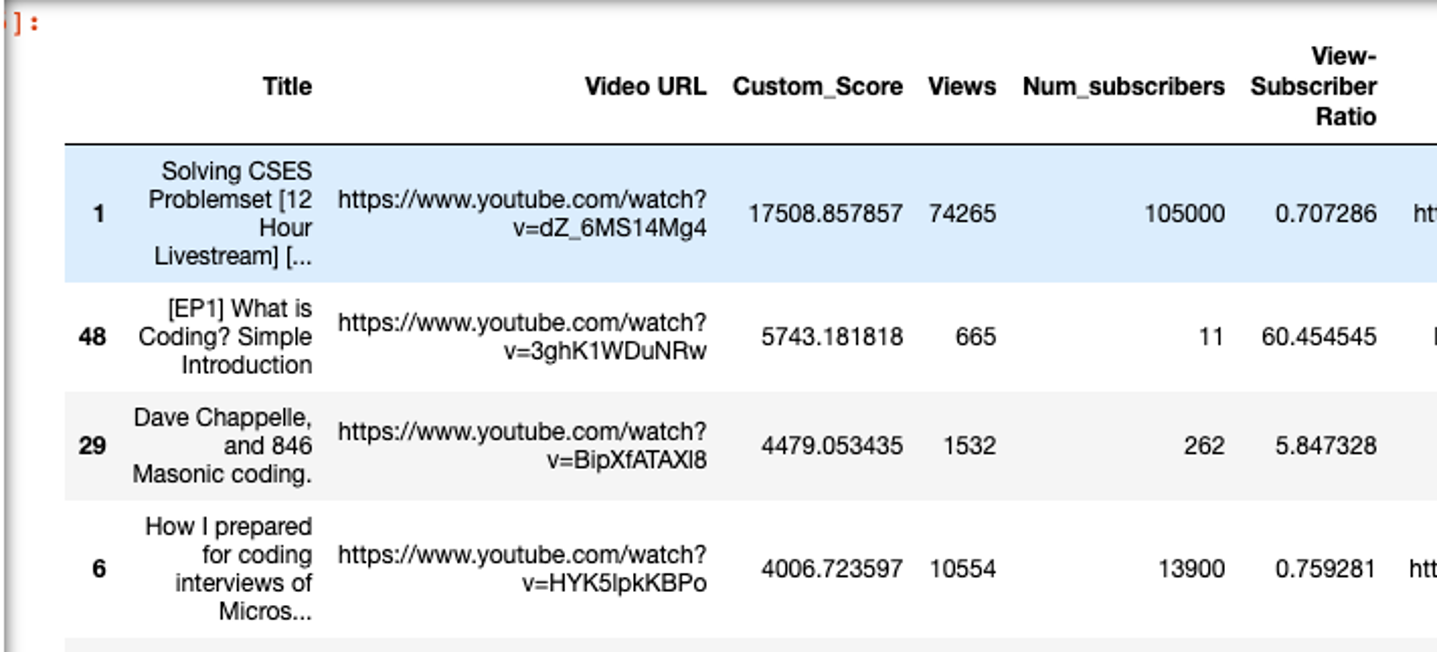 |
|---|
| While the top video looks potentially interesting, the second and third aren’t really what I was looking for. |
I took some efforts to remove these negative edge cases:
- I set the minimum number of views at 5000
- I set the maximum view-to-subscriber ratio to 5
I played around with various thresholds and these ones seemed to filter out these low-sub low-view videos pretty well. I tested the code on a few different topics and was starting to get pretty decent results.
However, there was another problem I noticed: Videos that had been published longer ago had a higher chance of getting more views. They simply had longer to accumulate them.
My plan was to run this code once a week, so I decided to restrict the search to videos published in the last 7 days.
I also added ‘days since published’ into the ranking metric. I decided to divide the previous score by the number of days, so that the final metric was proportionate to how long the video had been out for.
I tested my code further, and found I was quite consistently identifying great videos that I wanted to watch. I played around with different variations and weighting of different components of my formula, but I found it to be an inexact science, so I settled on the following formula which I found balanced simplicity with effectiveness:
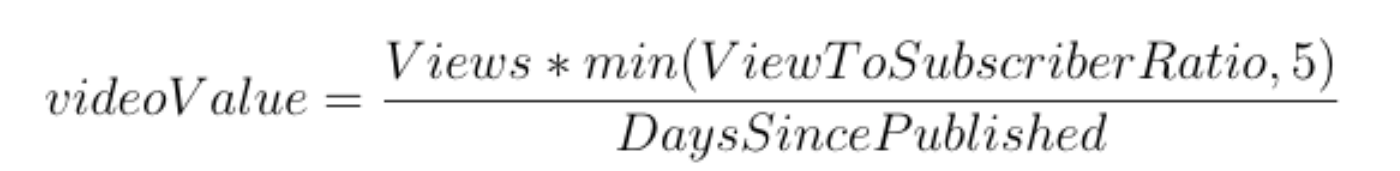
🔬 Testing my new tool
First, I tested using the query term ‘medical school’. I got the following results:
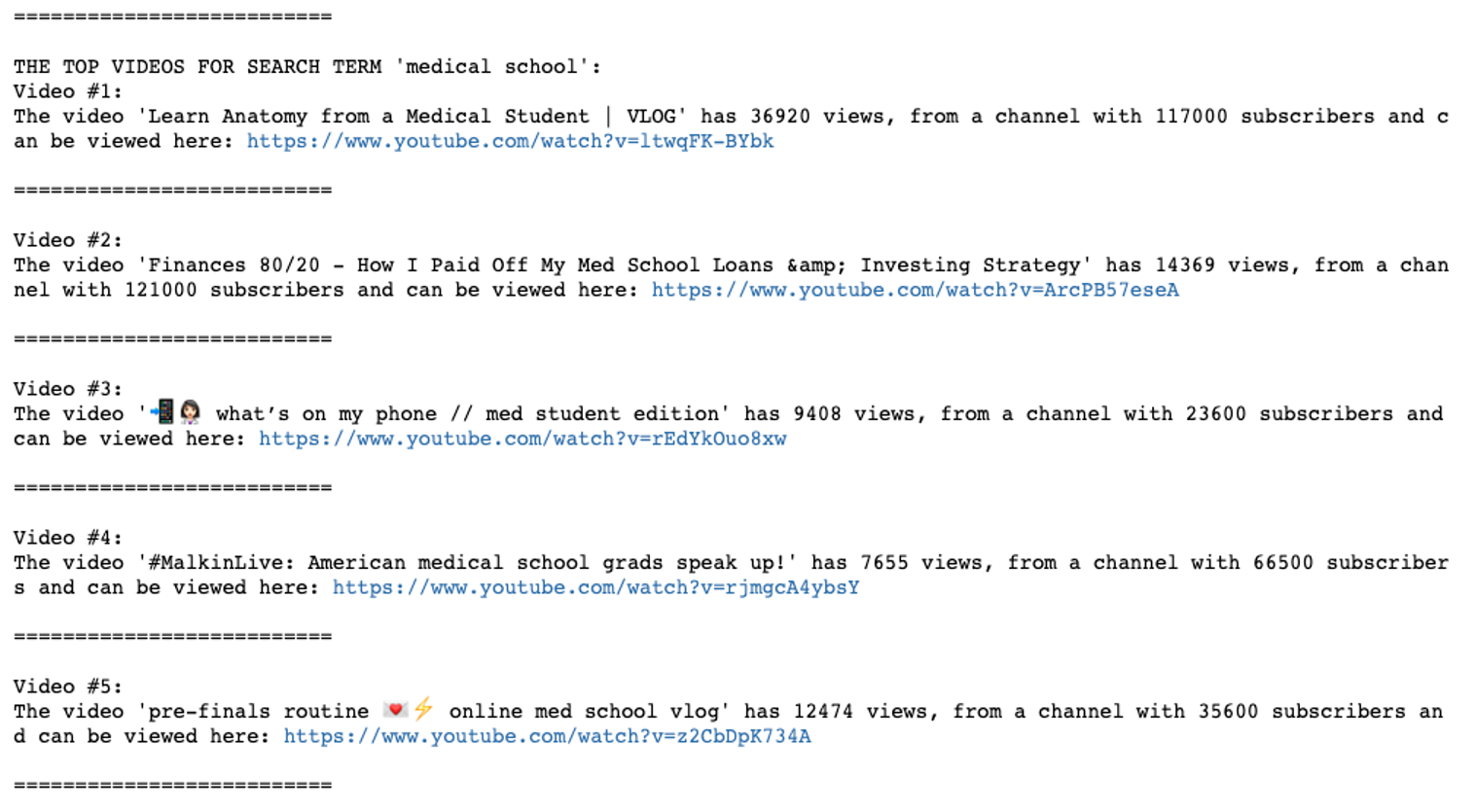
I then went to YouTube and manually searched for videos related to medicine and medical school. I found that my tool had captured all the ones I’d be interested in watching. In particular, the second video by a doctor called Kevin Jabbal was one that enjoyed.
I tested on another search term; ‘productivity’, and was again pretty happy with the results:

The second video was a slightly rogue one — and not the type of video I was looking for. But I couldn’t think of a simple way to screen out these videos, which were picked up due to an alternative meaning of the search term.
Several months ago, OpenAI shared a really interesting new neural network called ‘GPT-3’. I decided to test my video finder with ‘GPT-3’ as a search term and found this video:
It’s an interesting video from a creator with only a few thousand subscribers.
If I make the same search on YouTube.com, I have to scroll past videos about GPT-3 from all the big channels before finally finding the above video in 31st place.
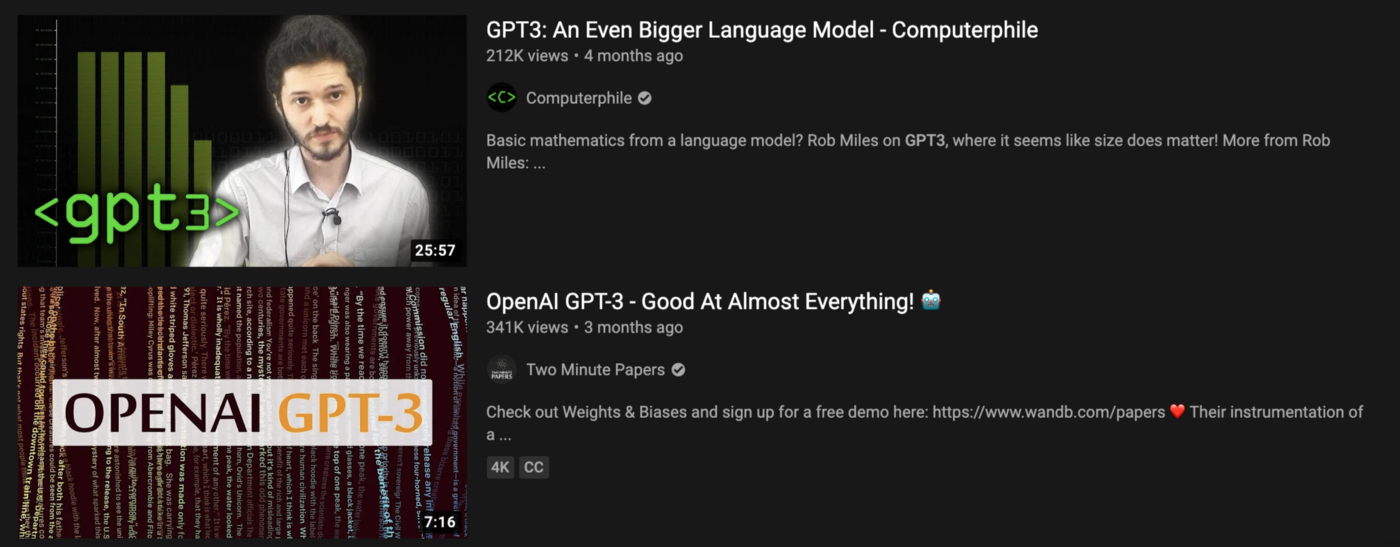 |
|---|
| GPT-3 videos from channels with larger audiences |
Finding these interesting videos with fresh perspectives is much easier using the Video Finder code I wrote.
Over the last few months, I’ve tried with multiple different search terms based on my interests, such as ‘artificial intelligence’, ‘medical AI’ and ‘Python programming’. Pretty much without fail, there’s been at least one interesting video in the top five that the Video Finder suggests.**
🖋 Setting up the workflow
I tidied up all my code and uploaded it to GitHub.
On a high-level, my code now worked as follows:
- Use the search terms, search period and API key to extract video information from YouTube
- Parse out the video metrics of interest
- Use the ‘value function’ to rank these videos based on predicted interest
- Store the relevant video information into a DataFrame
- Print details (including links) of the top 5 videos to the console
I wanted a way to automatically run this script and had decided to use AWS Lambda (a serverless platform). Lambda lets you write code which lies dormant until it is triggered (e.g. once per week, or based on an event).
My perfect workflow would have been to automatically email myself the list of videos every week using Lambda. That way I could pick out the videos from the past I wanted to watch the forthcoming week, and I’d never have to visit the YouTube home page again.
However, this didn’t work out.
This was my first time using Lambda and, try as I might, I just couldn’t get all the imported libraries to work at the same time. To execute, the code needed the boto3 email client, OAuth for the API call, Pandas for storing results and many sub-dependencies. Ordinarily, installing these packages is fairly trivial, but on Lambda there were extra challenges. Firstly, there are memory limits for uploads, so I needed to zip the libraries and unzip them after being uploaded. Secondly, it turns out that AWS Lambda uses custom linux which can make it trickier to import the correct, cross-compatible libraries. Thirdly, my Mac was behaving weirdly with its virtual environments.
After putting around 10–15 hours into scouring StackOverFlow, uploading and re-uploading different codebases and consulting several friends, I still couldn’t get it to run. So eventually, much to my frustration, I decided to give up. (if you have any good ideas, let me know!)
So instead, I settled for a plan B: I manually run the script on my local computer once a week (after an automatic email prompt). To be honest, it’s not the end of the world.
🔖 Closing thoughts
All-in-all this was a really fun project. I learnt how to use the YouTube API, gained familiarity with AWS Lambda and created a tool that I can use going forward.
Using my code to decide what videos to watch does seem to have boosted my productivity, as long as I have the discipline not to click on too many ‘follow-on’ links. It’s possible that I miss some interesting videos, but my aim isn’t to comprehensively catch all good videos worth watching (I don’t think that’s possible). Rather, I want to raise the bar on the quality of the videos I do watch.
This project is just one of many ideas I have around automating information processing. I believe there’s huge potential for us to boost our productivity and reclaim our time through intelligent digital minimalism.
If you’re interested in joining my journey, you can follow on my mailing list and YouTube channel.
👣 Potential next steps
On the whole, the project is still pretty rough and there’s a lot more I could do.
- The metric for ranking videos is pretty rough and I could refine it further. A natural next-step would be to incorporate the like/dislike ratio.
- There’s also a lot of dependency on search terms. If the text isn’t in the title or description, the video won’t get picked up. I could explore ways to get around this.
- I could also build an interface where users simply enter search terms and search period. This would make it more accessible, and could also allow users to view the video without ever going to youtube.com.
- At present, the code is pretty slow to run. I didn’t put much effort into optimising speed given I only plan to run it once per week. But there are some obvious inefficiencies that I could improve.
🔗 Other useful links
Similar projects:
YouTube API:
- Official documentation
- Sample API code
- Series on using the YouTube API (Indian Pythonista)
- Alternative series on using the YouTube API (Corey Schafer)
AWS Lambda:
Many thanks to Luke Harries, Josh Case, Oscar Bennett and Mustafa Sultan for their feedback on this blog and code.
