Systematically Improving RAG Applications
These are notes I made from this maven course by Jason Liu. I also gave a guest lecture on the course here.
Notes
RAG is basically a recommender system wrapped in LLMs at either end:  11.09.45.png)
A high-level pathway is:
- Define overall metrics (precision, recall) for your system. Get data (either from users or synthetic) to get these scores and test alternative approaches.
- A high leverage way to initially improve performance is finetuning embedding and re-ranker models
- As user volume increases, start to segment users to identify which queries are handled well and which are less well.
- Build out alternative retrieval approaches that work well for these specific segments.
- Create a router for selecting the appropriate retrieval approach for each segment.
- All of these components can be improved - and you can systematically iterate and improve on them.
Evaluating RAG systems
- There’s a bias towards working on generation rather than retrieval - because outputs of generation is what you see. But many generation issues are actually retrieval issues in disguise.
- Retrieval is also easier to text - you can run tests quickly and for very low cost (cf. generation test which are expensive to run, get expensive if you use e.g., LLM as judge)
- Precision and recall are the core metrics for retrieval. Helpful to look at precision@K and recall@K to see what fraction of top docs are relevant and what fraction of relevant docs are in top K (respectively).
- Generate synthetic data for each stage of the pipeline; principally, retrieval and reranking.
- Generating synthetic data is best if you already have some user data. Use it for few shot examples for generation.
Finetuning re-rankers and embedding models
- While finetuning language models is expensive, hard and may not actually improve performance - finetuning rerankers and embeddings can be a relatively easy way to get significant performance boost.
- This used to be expensive (in pre-LLM days), but no longer because you can generate synthetic data using LLMs
- Even 100 data points can be a good starting point for improving performance. 1000+ even better.
- The same data that you synthetically generated for testing can be used to finetune embedding and reranker models.
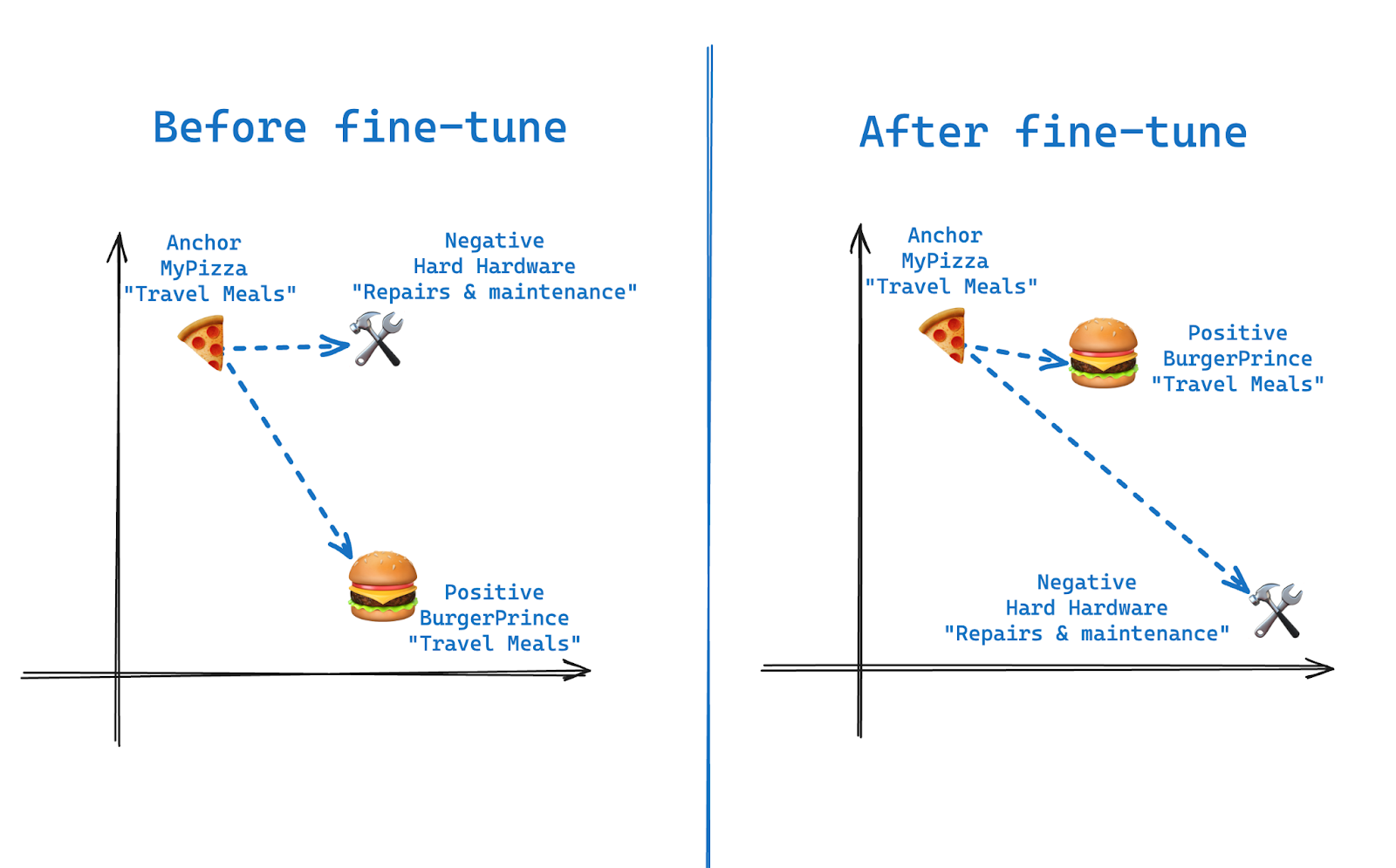
- You can finetune with question/answer pairs, but ideal is ‘triplets’ of question, positive example and negative example. This is a type of contrastive learning. The aim is to move positive examples closer and negative examples further away from your anchor/query (source):
- You ideally want to bake collection of these examples into your UX, so that users are automatically labelling data for you. Could be thumbs up / down, swipe left / right, select one option and not another option.
- Rerankers very often improve performance, although can introduce modest latency increase.
- You don’t need task-specific models, and there may even be performance improvement from using the same embedding/reranker models across different tasks / indices. E.g., if you have three indices of summaries, chunks, and table/image summaries.
- The intuition here is that you’re finetuning the models to better understand your data, and the traits that make your data unique to your use case are true across all your data sources.
- As of date of course, Cohere’s reranking models are best - easy both to embed and train.
Segmenting user data
- Segmenting data gives great insight on how yours users use your product and where performance can be improved
- One way to segment is perform clustering of the embeddings.
- Once you identify segments, you can take the following actions. (Top left is where you should focus your efforts.)
- You can prioritise work to improve segments using the following equation:
- $\text{Expected Value} = \text{Impact} \times \text{Percentage of queries} \times P(Success)$
- All segments where issues in performance can be divided into due to ‘lack of inventory’ or ‘lack of capabilities’
- Lack of inventory = not enough content in knowledge base = not enough rows in your database. May see low cosine similarities, lexical search returning 0 results, LLMs not citing any chunks. Could be product issue (e.g., customer not providing data they said they would, data not being ingested correctly).
- Lack of capabilities = your RAG system isn’t do well enough at retrieving = not enough columns in your database (e.g., not enough metadata to filter). One approach to improve may be better metadata filtering -> as per next section.
 11.43.40.png)
Multimodal RAG, Metadata Filtering and Routing
- Two key levers for improving performance are: extract structured metadata (potentially using LLMs) or generates summaries of data (which you can then embed and query too - like metadata).
- For all the queries you might see, you should ask what metadata might exist that would make the search easier
- There are also different entity-specific search indices you may want to make for different data types (for multimodal RAG):
- For images, you can generate descriptions. But avoid generic description (e.g., “this is two people arguing”) - think about the kinds of queries you may be answering and thus what sort of description matters.
- For tables, you could generate summaries, you could directly incorporate the table metadata for retrieval, you could pass full tables into long context models, or you could consider generating SQL queries with a python interpreter for querying them
- Once you have the different metadata, summaries, indices, you can define function calls which leverage them. You now have two components to assess: how well does my retriever get the correct data and how well does my LLM select the correct retriever.
Other notes
Two common retrieval techniques are:
- semantic search - embed documents and queries, measure semantic similarity
- lexical search - based on keywords. algorithms like BM25 which are based TF/IDF (which looks at frequency of words compared to their overall frequency across all documents)
Hybrid search is when you use both in combination for retrieval. You can also use one approach for retrieval and the other for reranking (i.e., a semantic retriever then lexical reranker or vice versa).
There’s also generative retrieval, where you train a model to generate identifiers / pointers to relevant documents. A common approach is ‘semantic IDs’, which are features of the items you’re retrieving. At inference time, the model converts your query to the semantic IDs, which can be used to retrieve the relevant items.