Relying only on offline evals is playing with fire: why you must evaluate on live production data
So you’ve followed the rule book: you’ve created your labelled datasets, used them to iterate against as you improve your LLM product, and you’re going live with early customers. Metrics look good, you’re excited and expecting great customer feedback.
But then you go live and reality hits hard. Endless customer complaints about failure cases. (How come these never showed up before?) Customer confidence tanks. You scramble to identify and fix the problems - but each time you fix one, another problem pops up. You’re playing whack-a-mole with LLM failure cases. By the time you get on top of the problems, it’s too late - your customers are gone.
What did you do wrong?
The False Comfort of Offline Evaluations
“Offline” datasets are collections of inputs with desired outputs that can be used to assess performance. They’re “offline” because they’re static snapshots of historical data, disconnected from the live flow of real user interactions.
These offline testing datasets are helpful insofar as they are an accurate representation of the new data coming into your system - the problem is that this isn’t always the case.
Firstly, there’s data drift. The input to your LLM product changes over time. Offline eval datasets start to become out-of-date the moment you create them.
Then, there are edge cases that your offline dataset won’t contain. As you process more inputs, you will see more and more edge cases that cause your product to fail. By definition, these aren’t represented in your offline dataset.
The more complex your input space, the more likely that your offline dataset will not capture the true heterogeneity of your input. You’ll need more and more data points to capture the breadth of the input space, but then performance on edge cases can got lost in the aggregate metrics.
Evaluating on live production data
To truly understand how you’re performing, you need to assess the outputs your product is producing from live input data. The more real-time those assessments the better.
One option is in-built customer feedback. If possible, get your customers to explicitly or implicitly tell you, in real-time, how helpful the model output is. Explicitly might be asking “how helpful was this output?”, while implicitly might be measuring whether they used the LLM product output. The challenge with explicit feedback is that here you’re dependent on customer’s providing feedback - when they’re just thinking about doing their work and moving on.
Another option is human reviews of outputs. You can build your own team and scoring system to do this. This can provide valuable, in-depth insight on a subset of outputs. The problem is: this doesn’t scale. (If it did, you might as well never use the LLM in the first place!)
A third option is automated online evals, which assess performance real-time. A popular method for this is the “LLM-as-judge”: you can pass your LLM outputs into another LLM which generates a score based on a defined scoring system. The scoring system could be anything: from confidence in the correctness of a decision to ‘traits’ of the LLM output such as conciseness, tone and helpfulness.
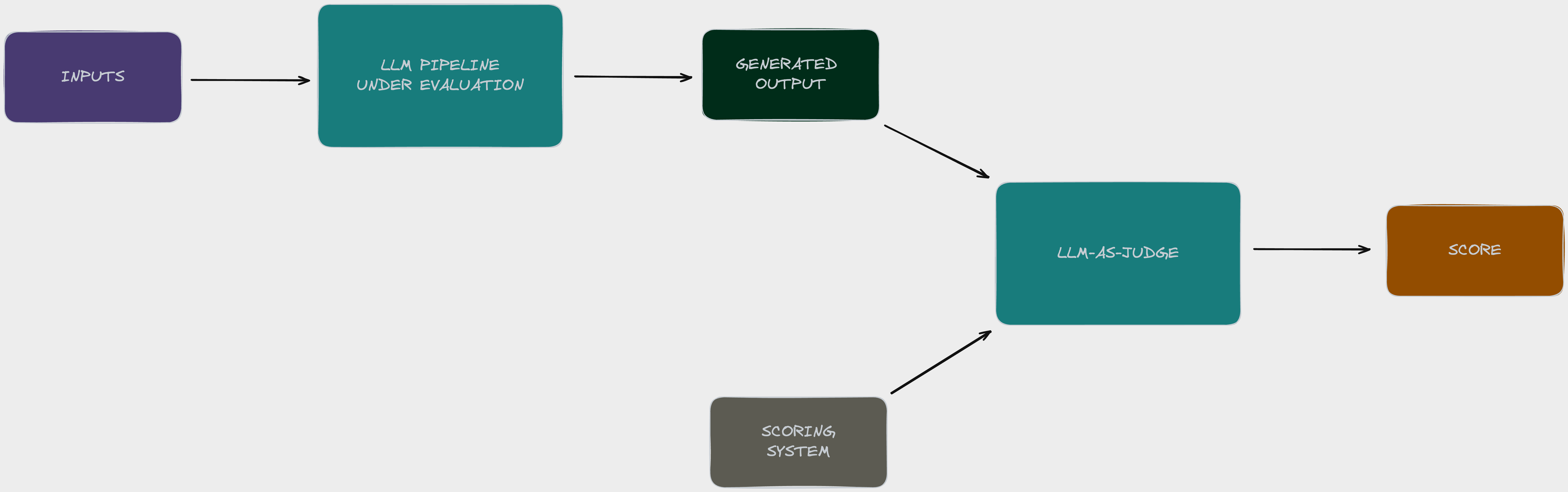
Using an LLM to assess your LLM output naturally begs the question: how do you validate your LLM validator? At Anterior we built a sophisticated human-in-the-loop system to do so, which I describe in detail here.
In conclusion
So while offline evals can be a helpful tool for iterating on LLM products, they are necessary but not sufficient. You need to analyse live production outputs to truly know how you’re doing, to identify issues proactively and thus respond more quickly - and keep customers happy.
Comments powered by Disqus.