5 ways to reduce the risk and impact of hallucinations in your LLM product
I’ve been building apps powered by LLMs for the past 2 years - mostly in healthcare where the stakes are high.
The single most common question I get is:
“So.. how do you deal with hallucinations?”
My response is typically a combination of the following 5 points:
1. Operate in an environment where hallucinations matter less
I think about LLM products along two axes: impact and control.
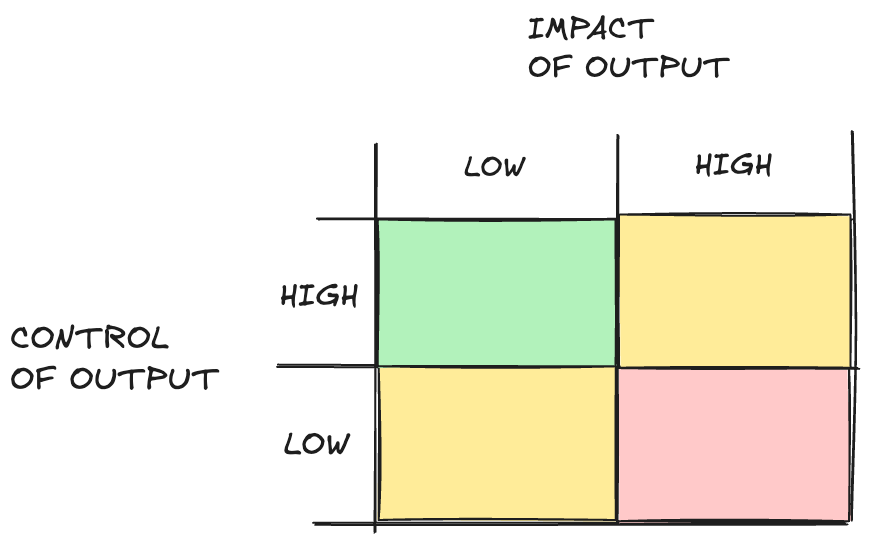
Impact of the LLM output would be high if eg. the LLM makes a medical decision which gets blindly followed.
Impact of LLM output is low if there are many checks and balances between the LLM output and the real-world impact.
Control of output is high if the model if the LLM output is constrained. Eg. the LLM must give one of three different discrete options.
Control of output is low if the model creates a large amount of unstructured free text output (such as a clinic letter).
It’s way easier to operate in the low impact of output + high control of output segment of the matrix.
I currently work at Anterior, a $95m start-up using LLMs to automate decisions in healthcare administration. We made the deliberate choice to operate in a space where those checks-and-balances already exist.
The existing flow of prior authorisation: when administrative staff or nurse thinks there isn’t enough evidence to support a treatment decision, it gets escalated to a doctor.
AI neatly slots in so now its: If AI pipeline thinks there isn’t enough evidence to support a treatment decision, it gets escalated to a doctor.
2. Make the tasks easier for your LLM
In my experience, LLMs are mostly likely to hallucinate when they’re stretched by what they’re being asked to do. Ie. when the task is at the limit of their capabilities.
You can make tasks easier by:
(1) Breaking the task down into multiple steps, each with defined inputs and outputs.
This also helps you understand what steps the model struggles with. You can monitor this by examining the inputs and outputs of each step for a bunch of examples.
Check this out for more thoughts on this.
(2) Reducing the amount of content passed into a single LLM call (ie. using retrieval-augmented generation)
Rather than feeding in massive amounts of text, identify the most relevant text and just pass that.
The ‘traditional’ RAG paradigm is to use vector embeddings and semantic search, but you can equally identify the most relevant text in others ways (such as giving it to a long context model and asking it to identify the relevant parts).
This also has the advantage of making inference quicker and cheaper because the model doesn’t have to process as much information.
3. Use throwaway structured reasoning
This is a “hack” I came up with 6 months ago and was since shared by openAI as well.
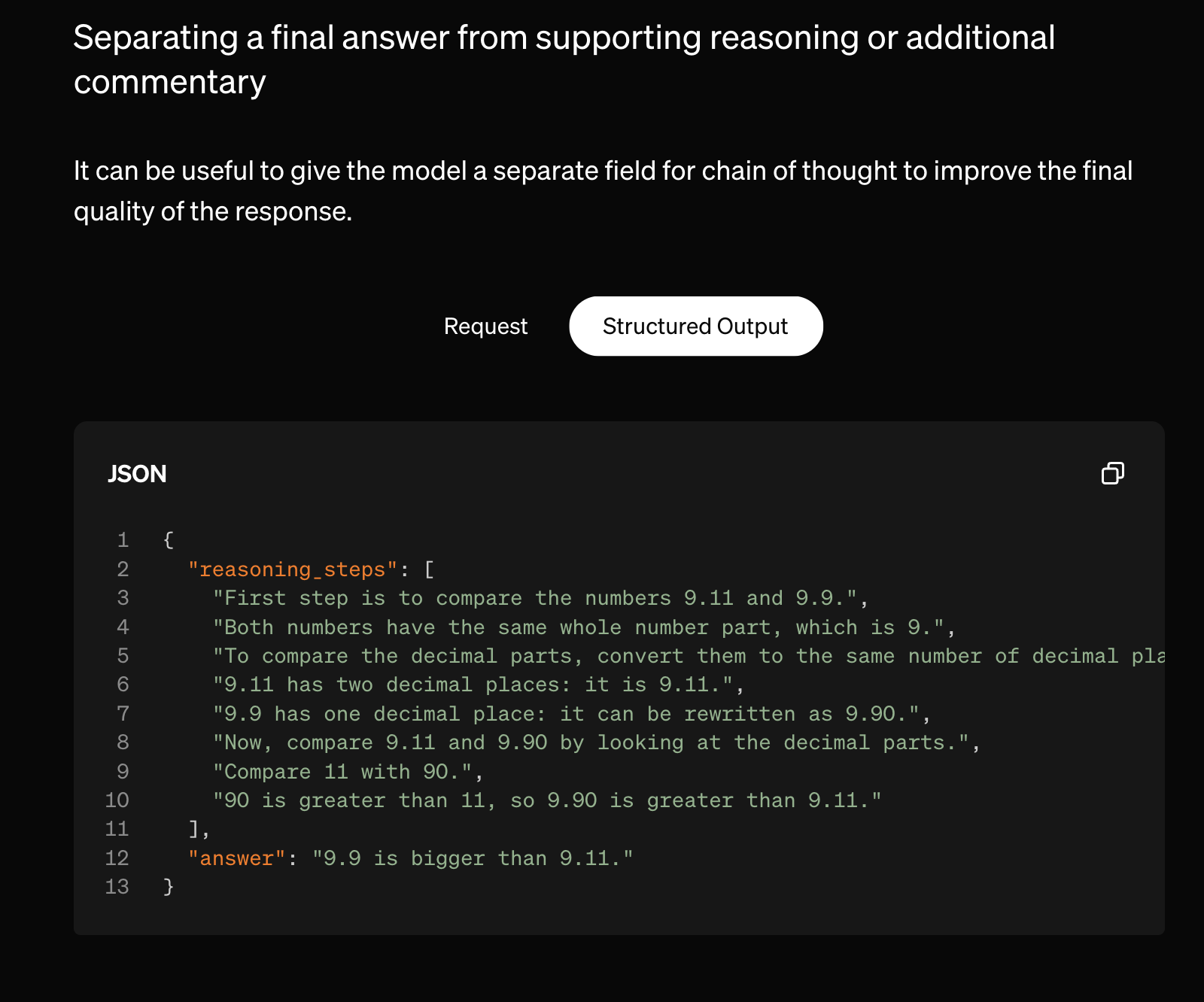
LLMs do better when you ask them to reason first before making a decision. (If you ask them to make a decision then reason, their reasoning will often anchor on justifying the decision - even if the decision isn’t correct).
LLMs are also more consistent when you constrain them to output in a structured format (like a dictionary or JSON).
You can combine these by asking the LLM to output in a structured format which includes “reasoning steps” first and then gives an answer.
This forces the model to “think” things through before giving the answer, which reduces its risk of hallucination.
4. Use more powerful models
In general, better models are less likely to hallucinate.
The best “off-the-shelf” models right now are those provided by openAI or anthropic - but you can equally create your own ‘best’ models by fine-tuning an open-source model for your use case.
5. Monitor for hallucinations using evals
While your LLM may perform great (without hallucinations) on most data it receives, there is always a risk that ‘edge case’ data could cause it to hallucinate.
It’s not possible to know what kind of input will lead to those hallucinations - so you should set up a way to monitor it.
One way to do that is using hallucination evals (1, 2, 3), which check how much the LLM output is anchored on the provided context.
Running these evals on the background for all LLM outputs you generate will identify LLM inputs that currently cause hallucinations. You can then fix them by tweaking prompts or updating the sequence of LLM calls used.
It’s helpful to keep track of these inputs as a dataset that you can keep testing against to prevent regressions from future changes.
You can’t guarantee that LLMs won’t hallucinate
With all that being said, there’s no way to 100% guarantee that your LLMs won’t hallucinate.
The best we can do is build systems around our models which minimise the risk and impact of hallucinations - and which enable us to quickly identify and respond when our AI pipelines aren’t working as intended. This is particularly important for ‘mission critical’ industries like healthcare, to ensure the safe and effective use of LLMs.
Comments powered by Disqus.